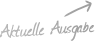

Nvidia-Aktie auf Rekordkurs: Warum der Grafik-Chip-Hersteller mit Hilfe einer technischen Revolution Anleger weiterhin reich machen dürfte
Aufklärung über Eigenpositionen: Diese Aktien aus dem Artikel halten TraderFox-Redakteure aktuell
Tipp: 200 NVIDIA Corp. Aktien für nur 2,00 USD handeln über die
CapTrader: TraderFox-Edition
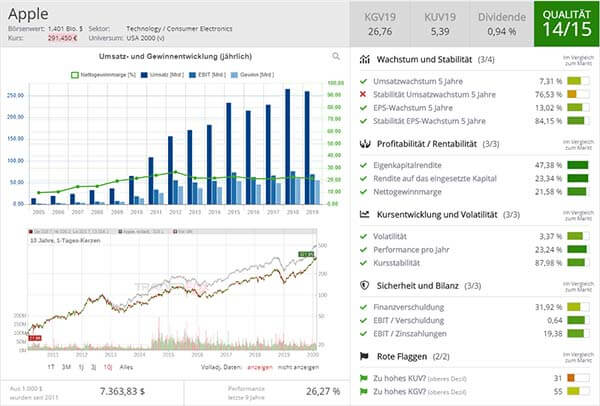
Der Aktienkurs von Nvidia ist im Februar und im März im Zuge der Coronaviurs-Baisse zwar ebenfalls deutlich abgesackt. Seitdem hat der Titel aber wieder markant zugelegt. Gemessen am Zwischentief von 196,40 USD vom 16. März ergibt sich derzeit fast eine Verdoppelung. Der langfristige Aufwärtstrend ist angesichts der gerade frisch aufgestellten Kursrekorde zweifelsfrei wieder aufgenommen. Von April 1999 bis heute ist die Aktie bereits von 1,37 USD auf 384,49 USD nach oben geklettert. Das entspricht einem Plus von 27.965 %. Mit dem Titel sind somit schon viele Langfrist-Investoren reich geworden. Trotz dieses kolossalen Anstiegs scheint der Entwickler von Grafikprozessoren und Chipsätzen aus heutiger Sicht aber an der Börse noch immer viele gute Jahre vor sich zu haben - und somit über das Potenzial zu verfügen, weiteren Mehrwert aus Anlegersicht zu schaffen.
Warum das so sein könnte, hat mit der technischen Revolution im Zuge der Künstlichen Intelligenz-Welle zu tun. Zumindest ist das die Ansicht von Alison Porter, Graeme Clark und Richard Clode. Denn aus der Perspektive der Manager des globalen Technologie-Portfolios bei der Investmentgesellschaft Janus Henderson Investors dürfte die jüngste Markteinführung von Ampere, Nvidias neuestem Grafikbeschleuniger, für die Entwicklung von Cloud Computing, künstlicher Intelligenz und Gaming-Grafiken wegweisend sein. Was das Portfolio Manager-Trio konkret zu ihrer positiven Haltung gegenüber diesem Tech-Höhenflieger bewegt, begründen sie in einer aktuellen Einschätzung ausführlich und aufschlussreich wie folgt:
Dass der CEO von Nvidia gezwungen gewesen sei, eine "Küchen-Keynote" zu halten, um den neuen Grafikprozessor (GPU) des Unternehmens namens Ampere offiziell vorzustellen, sei eine weitere Premiere in der neuen Normalität der COVID-19-Welt gewesen. Das habe jedoch einer der wichtigsten Markteinführungen neuer Halbleiter in den letzten Jahren, die erhebliche Auswirkungen auf künstliche Intelligenz (KI), Cloud Computing, Spiele und das Moore‘sche Gesetz hat, keinen Abbruch getan.
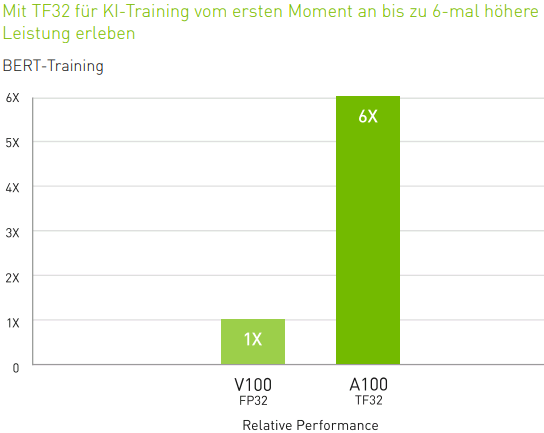
Ampere komme mehr als drei Jahre nach der Einführung von Nvidia Volta Ende 2017 auf den Markt. Voltas Leistungssprung und die Optimierung für künstliche Intelligenz (KI) seien damals ein wegweisender Schritt für die Einführung von Grafikprozessoren zur Beschleunigung von Arbeitslasten in der Cloud sowie für KI-Training gewesen. Nvidia sei dank der Kombination seiner überlegenen Hardware und der seit 10 Jahren getätigten Investitionen in den firmeneigenen Softwarestack CUDA zum De-facto-Standard für KI-Training geworden. Die Einführung von Volta habe zu einem entscheidenden Wendepunkt in der KI geführt, und seit der Einführung von Volta hätten sich Nvidias Einnahmen im Bereich der Rechenzentren innerhalb von drei Jahren auf mehr als 1 Mrd. USD pro Quartal verdoppelt.
Computing (Rechenaktivitäten) und KI seien untrennbar miteinander verbunden, wobei das eine die Nachfrage nach dem anderen ermögliche und umgekehrt. Die Wende in der KI, die wir in den letzten Jahren erlebt hätten, sei dadurch ermöglicht worden, dass die Rechenleistung ein Niveau und einen Kostenfaktor erreicht habe, die neuronale Netze und tiefes Lernen möglich machten. Neue, komplexere neuronale Netze wie die für die Verarbeitung natürlicher Sprache verwendeten BERT-Modelle, die Amazon Alexa und Google Home zugrunde lägen, seien jedoch wesentlich komplexer und größer als frühere Modelle. Dies erfordere einen Prozessor der nächsten Generation, der diese Anforderungen erfülle und die nächste Welle der KI-Innovation anstoße.
Quelle: Nvidia
Quelle: Nvidia
Was in Ampere steckt
Ampere stelle jenen gewaltigen Schritt nach vorne dar, der möglicherweise einen weiteren Wendepunkt in der KI herbeiführen könnte. Ampere baue auf dem Moore‘schen Gesetz auf, das eine Steigerung der Dichte von Transistoren fordere. So packe Ampere 54 Mrd. Transistoren auf einen Chip, der etwa so groß ist wie Volta, der lediglich 21 Mrd. hatte. Nvidia verwende allerdings den 7-nm-Fertigungsprozess von Taiwan Semiconductor Manufacturing Co. (TSMC) und nicht die führende 5-nm-Technologie, die Apple in diesem Jahr im neuen iPhone einsetze, was die Herausforderungen des Moore‘schen Gesetzes verdeutliche.
Der vom Moore‘schen Gesetz verursachte Druck zwinge Halbleiterunternehmen, architektonische Verbesserungen vorzunehmen, um die von den Kunden geforderten Leistungssteigerungen weiter voranzutreiben. Für Ampere setze Nvidia die CoWoS-Packaging-Technologie von TSMC ein, um Speicher der nächsten Generation mit hoher Bandbreite besser zu integrieren, sowie Infiniband-Gewebe vom kürzlich erworbenen Unternehmen Mellanox. In beiden Fällen reduzierten diese Hochgeschwindigkeits-Schnittstellen Engpässe bei der Übertragung großer Datenmengen zwischen den Prozessoren oder vom Speicher zu den Prozessoren.
Verlagerung der Rechenleistung vom Server zum Rechenzentrum
Das wichtigste neue Merkmal von Ampere, das erhebliche Konsequenzen mit sich bringe, sei die Fähigkeit dieses Grafikprozessors, auf bis zu 7 verschiedene Threads zu virtualisieren. Dies spiele bei Nvidias Vision, die Rechenleistung vom Server auf die Ebene des Rechenzentrums zu verlagern, eine Schlüsselrolle. Genauso wie VMWare Server mit seiner Software virtualisiert habe, stelle sich Nvidia eine Welt vor, in der virtualisierte Hard- und Software es einem Hyperscaler (wie Google, Facebook oder Amazon, der im Bereich der Datenverarbeitung – typischerweise in den Bereichen Big Data oder Cloud Computing – enorme Größenordnungen erreichen könne) ermöglichten, jegliche Arbeitslast überall in seinem Rechenzentrum auszuführen, um so die Effizienz zu maximieren.
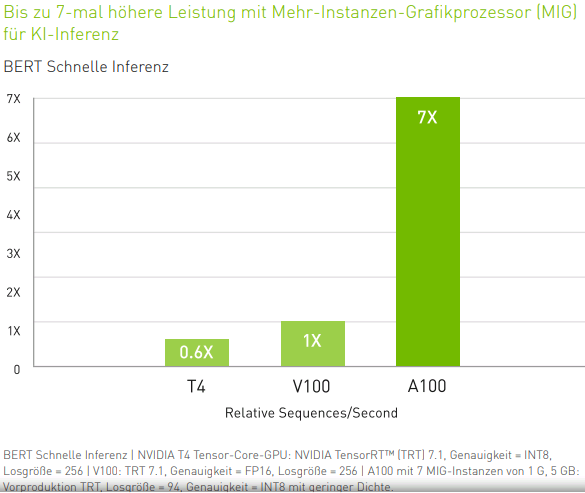
Die individuelle Anpassung von Servern für eine bestimmte Arbeitslast werde der Vergangenheit angehören. Nvidia sehe Ampere als universellen Beschleuniger für Cloud-Workloads. In diesem Sinne übernehme Ampere sowohl KI-Training als auch Inferenzierung innerhalb eines einzigen Systems. Die hohen Leistungsanforderungen des KI-Trainings mit unglaublich komplexen neuronalen Netzen erforderten in der Vergangenheit im Vergleich zu den leichteren Anforderungen für die KI-Inferenzierung, bei der die Ausgabe dieses KI-Trainingsmodells auf die reale Welt angewendet werde, einen anderen Prozessor. Ampere könne erstmalig beide Funktionen effizient ausführen, da die Inferenzierung virtualisiert werde, wodurch die äquivalente Leistung eines Volta-Chips für bis zu 56 Benutzer innerhalb eines einzigen Ampere-Systems zur Verfügung stehe.
Senkung der Rechenkosten
Das Moore‘sche Gesetz sei seit Jahrzehnten eine wichtige Triebkraft hinter den Zugewinnen von Technologieaktien. Die Fähigkeit, bei gleichen Kosten eine doppelt so hohe Rechenleistung zu erbringen, resultiere in der Exponentialkurve, die das Herzstück jeglicher technologischer Innovation darstelle. Ampere von Nvidia sei die nächste große Iteration dieses Prinzips und liefere noch sehr viel mehr als das. Ampere biete eine bis zu 20 Mal höhere Leistung für Arbeitslasten, da das Moore‘sche Gesetz mit umfassenderen Hardware-Innovationen sowie Software-Innovationen verknüpft werde, sowohl in Bezug auf die Virtualisierung als auch innerhalb von CUDA, der proprietären Programmiersprache, die von den meisten KI-Forschern verwendet werde.
Nvidia habe mit Ampere zudem Unterstützung für CUDA Sparsity eingeführt, wodurch komplexe KI-Modelle viel schneller ausgeführt werden können, indem weniger wichtige Modellgewichte (die bestimmen, wie viel Einfluss eine Eingabe auf die Ausgabe hat) während des iterativen Prozesses ausgeblendet würden, so dass sich der erforderliche Berechnungsaufwand reduziere. Werde die ganze Kraft des breiten Technologiespektrums von Nvidia zum Tragen gebracht, ergebe sich ein beeindruckendes Ergebnis. Es seien mehrere Beispiele für Ampere-betriebene A100-Systeme präsentiert worden, die für 1/10 der Kosten und 1/20 des Stromverbrauchs dieselbe Leistung wie ein Volta-basiertes V100-System bringen würden. Visuell betrachtet bedeute das, einen Raum voller Server-Racks durch ein einziges Server-Rack zu ersetzen. Der CEO von Nvidia habe dies wie folgt formuliert: "Je mehr man kauft, desto mehr spart man". Das Unternehmen gehe davon aus, dass Ampere maßgeblich dazu beitragen werde, die Kosten für die Entwicklung und Bereitstellung von Cloud-Computing und KI zu senken. Dementsprechend seien beim Unternehmen bereits Bestellungen für Ampere von großen Hyperscalern wie Amazon Web Services, Microsoft Azure, Google Cloud, Alibaba Cloud und Tencent Cloud eingegangen.
Aufstieg in eine völlig neue Liga von Gaming-Grafiken
Auch wenn Nvidia noch kein Gaming-Produkt auf der Basis von Ampere angekündigt habe, werde dies allgemein im weiteren Verlauf dieses Jahres erwartet. In seiner Keynote-Rede habe der CEO von Nvidia auf die enormen Verbesserungen verwiesen, die Ampere im Bereich Ray-Tracing ermöglichen könne. Unter Ray-Tracing verstehe man die Fähigkeit, unglaublich lebensechte Grafiken mit voller Lichtbrechung zu erstellen. Dies erfordere enorme Mengen an Rechenleistung und sei für computergenerierte Bilder (CGI) in Hollywood-Blockbuster-Filmen eingesetzt worden. Mit Volta sei Ray-Tracing erstmals für PC-Spiele genutzt worden, da die Rechenleistung zu vertretbaren Kosten auf einer Standard-Gaming-Karte untergebracht werden konnte. Mit Ampere werde das Thema auf ein ganz neues Niveau angehoben.
Nvidia habe außerdem eine KI-Engine zur Verbesserung der Ray-Tracing-Leistung eingesetzt. Sie lerne, wie ein Bild mit sehr viel höherer Auflösung aussehe und welche Bewegungsvektoren für Live-Spiele-Videografiken benötigt würden. Damit könne sie vorhersehen, welche Pixel in einem zukünftigen Bild angezeigt werden müssten. Nachdem sich Ray-Tracing über einen Zeitraum von 2 Jahren hinweg immer mehr am Markt durchgesetzt habe, unterstützten inzwischen alle wichtigen Engines für die Spieleentwicklung Ray-Tracing. Gleiches gelte für Hit-Spiele wie Minecraft, Call of Duty: Modern Warfare und Battlefield V sowie die neue PlayStation 5-Konsole, die im weiteren Verlauf dieses Jahres auf den Markt kommen solle. Zukünftige Ampere-Gaming-Karten könnten das Ray-Tracing in PC-Spielen auf die nächste Stufe heben, während virtualisierten Amperes eine mögliche Schlüsselrolle in der Zukunft von Cloud-Gaming-Diensten zugeschrieben werde.
Janus Henderson-Fazit
Ganz gleich, ob Sie Gamer sind, Online-Dienste wie Amazon, Netflix oder Spotify nutzen, die in der Cloud eingerichtet wurden, oder mit KI-Diensten wie Amazon Alexa interagieren – viele Branchenexperten sehen die Einführung von Nvidias Ampere als einen großen Schritt nach vorn, der die Möglichkeit bietet, diese Dienste besser und kostengünstiger zu machen.
Zentrale Erkenntnisse
• Ampere spielt bei Nvidias Vision, Rechenaktivitäten vom Server auf die Ebene des Rechenzentrums zu verlagern und damit die Effizienz deutlich zu steigern, laut Janus Henderson eine Schlüsselrolle.
• Nvidia sieht Ampere als universellen Beschleuniger für Cloud-Arbeitslasten, der sowohl KI-Training als auch Inferenzierung in einem einzigen System effizient durchführen kann.
• Ampere wird enorme Verbesserungen beim Ray-Tracing (naturgetreue Grafiken) ermöglichen, wobei unter anderem eine KI-Engine zur Leistungssteigerung zum Einsatz kommt.
Glossar:
Grafikprozessor (GPU): führt komplexe mathematische und geometrische Berechnungen durch, die für die Grafikwiedergabe erforderlich sind.
Moore‘sches Gesetz: sagt voraus, dass sich die Anzahl der Transistoren, die auf einen Mikrochip passen, alle zwei Jahre ungefähr verdoppeln wird, wodurch die relativen Kosten sinken und die Leistung steigt.
Moore‘scher Druck: bezieht sich auf die seit langem vertretene Auffassung, dass die alle paar Jahre erwartete exponentielle Zunahme der Rechenleistung von Computern ihre Grenze erreicht hat. Da sich die Größenordnung der Chipkomponenten immer mehr der Größe einzelner Atome annähert, ist es heute teurer und technisch schwieriger, die Anzahl der Transistoren und damit die Verarbeitungsleistung für einen bestimmten Chip alle zwei Jahre zu verdoppeln.
Verarbeitung natürlicher Sprache: ein Zweig der KI, der Computern hilft, menschliche Sprache zu verstehen, zu interpretieren und zu manipulieren. Die Verarbeitung natürlicher Sprache bedient sich vieler Disziplinen, darunter die Informatik und die Computerlinguistik, um so die Lücke zwischen menschlicher Kommunikation und Computerverständnis zu schließen.
Virtualisierung: bezieht sich auf eine simulierte bzw. virtuelle Computerumgebung anstelle einer physischen Umgebung. Virtualisierung umfasst häufig computergenerierte Versionen von Hardware, Betriebssystemen, Speichergeräten und mehr. Dies ermöglicht es Organisationen, einen einzelnen physischen Computer oder Server in mehrere virtuelle Maschinen zu partitionieren. Jede virtuelle Maschine kann dann unabhängig interagieren und verschiedene Betriebssysteme oder Anwendungen ausführen, wobei die Ressourcen eines einzelnen Host-Rechners gemeinsam genutzt werden.
Arbeitslast: die Menge der Verarbeitung, die ein Computer zu einem bestimmten Zeitpunkt zu erledigen hat.
KI-Training: auch bekannt als maschinelles Lernen, ist eine Untergruppe der KI, die es Computersystemen ermöglicht, automatisch zu lernen und sich zu verbessern, ohne von einem Menschen programmiert zu werden.
Tiefes Lernen/neuronales Netzwerk: eine Untergruppe des maschinellen Lernens; es handelt sich um eine Reihe von Algorithmen, die darauf abzielen, zugrunde liegende Beziehungen in einem Datensatz durch einen Prozess zu erkennen, der die Funktionsweise des menschlichen Gehirns nachahmt.
KI-Inferenz: bezieht sich auf die Verarbeitung künstlicher Intelligenz. Während sich maschinelles Lernen und tiefes Lernen auf das Training neuronaler Netze beziehen, wendet die KI-Inferenz Wissen aus einem trainierten neuronalen Netzwerkmodell an und verwendet es, um ein Ergebnis abzuleiten.
Sparsity: wird zur Beschleunigung von KI verwendet, indem die für das tiefe Lernen erforderlichen Häufungen der Matrix-Multiplikation reduziert werden, so dass sich die Zeit bis zur Erreichung guter Ergebnisse verkürzt.
Warum das so sein könnte, hat mit der technischen Revolution im Zuge der Künstlichen Intelligenz-Welle zu tun. Zumindest ist das die Ansicht von Alison Porter, Graeme Clark und Richard Clode. Denn aus der Perspektive der Manager des globalen Technologie-Portfolios bei der Investmentgesellschaft Janus Henderson Investors dürfte die jüngste Markteinführung von Ampere, Nvidias neuestem Grafikbeschleuniger, für die Entwicklung von Cloud Computing, künstlicher Intelligenz und Gaming-Grafiken wegweisend sein. Was das Portfolio Manager-Trio konkret zu ihrer positiven Haltung gegenüber diesem Tech-Höhenflieger bewegt, begründen sie in einer aktuellen Einschätzung ausführlich und aufschlussreich wie folgt:
Dass der CEO von Nvidia gezwungen gewesen sei, eine "Küchen-Keynote" zu halten, um den neuen Grafikprozessor (GPU) des Unternehmens namens Ampere offiziell vorzustellen, sei eine weitere Premiere in der neuen Normalität der COVID-19-Welt gewesen. Das habe jedoch einer der wichtigsten Markteinführungen neuer Halbleiter in den letzten Jahren, die erhebliche Auswirkungen auf künstliche Intelligenz (KI), Cloud Computing, Spiele und das Moore‘sche Gesetz hat, keinen Abbruch getan.
Ampere komme mehr als drei Jahre nach der Einführung von Nvidia Volta Ende 2017 auf den Markt. Voltas Leistungssprung und die Optimierung für künstliche Intelligenz (KI) seien damals ein wegweisender Schritt für die Einführung von Grafikprozessoren zur Beschleunigung von Arbeitslasten in der Cloud sowie für KI-Training gewesen. Nvidia sei dank der Kombination seiner überlegenen Hardware und der seit 10 Jahren getätigten Investitionen in den firmeneigenen Softwarestack CUDA zum De-facto-Standard für KI-Training geworden. Die Einführung von Volta habe zu einem entscheidenden Wendepunkt in der KI geführt, und seit der Einführung von Volta hätten sich Nvidias Einnahmen im Bereich der Rechenzentren innerhalb von drei Jahren auf mehr als 1 Mrd. USD pro Quartal verdoppelt.
Computing (Rechenaktivitäten) und KI seien untrennbar miteinander verbunden, wobei das eine die Nachfrage nach dem anderen ermögliche und umgekehrt. Die Wende in der KI, die wir in den letzten Jahren erlebt hätten, sei dadurch ermöglicht worden, dass die Rechenleistung ein Niveau und einen Kostenfaktor erreicht habe, die neuronale Netze und tiefes Lernen möglich machten. Neue, komplexere neuronale Netze wie die für die Verarbeitung natürlicher Sprache verwendeten BERT-Modelle, die Amazon Alexa und Google Home zugrunde lägen, seien jedoch wesentlich komplexer und größer als frühere Modelle. Dies erfordere einen Prozessor der nächsten Generation, der diese Anforderungen erfülle und die nächste Welle der KI-Innovation anstoße.
Quelle: Nvidia
Quelle: Nvidia
Was in Ampere steckt
Ampere stelle jenen gewaltigen Schritt nach vorne dar, der möglicherweise einen weiteren Wendepunkt in der KI herbeiführen könnte. Ampere baue auf dem Moore‘schen Gesetz auf, das eine Steigerung der Dichte von Transistoren fordere. So packe Ampere 54 Mrd. Transistoren auf einen Chip, der etwa so groß ist wie Volta, der lediglich 21 Mrd. hatte. Nvidia verwende allerdings den 7-nm-Fertigungsprozess von Taiwan Semiconductor Manufacturing Co. (TSMC) und nicht die führende 5-nm-Technologie, die Apple in diesem Jahr im neuen iPhone einsetze, was die Herausforderungen des Moore‘schen Gesetzes verdeutliche.
Der vom Moore‘schen Gesetz verursachte Druck zwinge Halbleiterunternehmen, architektonische Verbesserungen vorzunehmen, um die von den Kunden geforderten Leistungssteigerungen weiter voranzutreiben. Für Ampere setze Nvidia die CoWoS-Packaging-Technologie von TSMC ein, um Speicher der nächsten Generation mit hoher Bandbreite besser zu integrieren, sowie Infiniband-Gewebe vom kürzlich erworbenen Unternehmen Mellanox. In beiden Fällen reduzierten diese Hochgeschwindigkeits-Schnittstellen Engpässe bei der Übertragung großer Datenmengen zwischen den Prozessoren oder vom Speicher zu den Prozessoren.
Verlagerung der Rechenleistung vom Server zum Rechenzentrum
Das wichtigste neue Merkmal von Ampere, das erhebliche Konsequenzen mit sich bringe, sei die Fähigkeit dieses Grafikprozessors, auf bis zu 7 verschiedene Threads zu virtualisieren. Dies spiele bei Nvidias Vision, die Rechenleistung vom Server auf die Ebene des Rechenzentrums zu verlagern, eine Schlüsselrolle. Genauso wie VMWare Server mit seiner Software virtualisiert habe, stelle sich Nvidia eine Welt vor, in der virtualisierte Hard- und Software es einem Hyperscaler (wie Google, Facebook oder Amazon, der im Bereich der Datenverarbeitung – typischerweise in den Bereichen Big Data oder Cloud Computing – enorme Größenordnungen erreichen könne) ermöglichten, jegliche Arbeitslast überall in seinem Rechenzentrum auszuführen, um so die Effizienz zu maximieren.
Die individuelle Anpassung von Servern für eine bestimmte Arbeitslast werde der Vergangenheit angehören. Nvidia sehe Ampere als universellen Beschleuniger für Cloud-Workloads. In diesem Sinne übernehme Ampere sowohl KI-Training als auch Inferenzierung innerhalb eines einzigen Systems. Die hohen Leistungsanforderungen des KI-Trainings mit unglaublich komplexen neuronalen Netzen erforderten in der Vergangenheit im Vergleich zu den leichteren Anforderungen für die KI-Inferenzierung, bei der die Ausgabe dieses KI-Trainingsmodells auf die reale Welt angewendet werde, einen anderen Prozessor. Ampere könne erstmalig beide Funktionen effizient ausführen, da die Inferenzierung virtualisiert werde, wodurch die äquivalente Leistung eines Volta-Chips für bis zu 56 Benutzer innerhalb eines einzigen Ampere-Systems zur Verfügung stehe.
Senkung der Rechenkosten
Das Moore‘sche Gesetz sei seit Jahrzehnten eine wichtige Triebkraft hinter den Zugewinnen von Technologieaktien. Die Fähigkeit, bei gleichen Kosten eine doppelt so hohe Rechenleistung zu erbringen, resultiere in der Exponentialkurve, die das Herzstück jeglicher technologischer Innovation darstelle. Ampere von Nvidia sei die nächste große Iteration dieses Prinzips und liefere noch sehr viel mehr als das. Ampere biete eine bis zu 20 Mal höhere Leistung für Arbeitslasten, da das Moore‘sche Gesetz mit umfassenderen Hardware-Innovationen sowie Software-Innovationen verknüpft werde, sowohl in Bezug auf die Virtualisierung als auch innerhalb von CUDA, der proprietären Programmiersprache, die von den meisten KI-Forschern verwendet werde.
Nvidia habe mit Ampere zudem Unterstützung für CUDA Sparsity eingeführt, wodurch komplexe KI-Modelle viel schneller ausgeführt werden können, indem weniger wichtige Modellgewichte (die bestimmen, wie viel Einfluss eine Eingabe auf die Ausgabe hat) während des iterativen Prozesses ausgeblendet würden, so dass sich der erforderliche Berechnungsaufwand reduziere. Werde die ganze Kraft des breiten Technologiespektrums von Nvidia zum Tragen gebracht, ergebe sich ein beeindruckendes Ergebnis. Es seien mehrere Beispiele für Ampere-betriebene A100-Systeme präsentiert worden, die für 1/10 der Kosten und 1/20 des Stromverbrauchs dieselbe Leistung wie ein Volta-basiertes V100-System bringen würden. Visuell betrachtet bedeute das, einen Raum voller Server-Racks durch ein einziges Server-Rack zu ersetzen. Der CEO von Nvidia habe dies wie folgt formuliert: "Je mehr man kauft, desto mehr spart man". Das Unternehmen gehe davon aus, dass Ampere maßgeblich dazu beitragen werde, die Kosten für die Entwicklung und Bereitstellung von Cloud-Computing und KI zu senken. Dementsprechend seien beim Unternehmen bereits Bestellungen für Ampere von großen Hyperscalern wie Amazon Web Services, Microsoft Azure, Google Cloud, Alibaba Cloud und Tencent Cloud eingegangen.
Aufstieg in eine völlig neue Liga von Gaming-Grafiken
Auch wenn Nvidia noch kein Gaming-Produkt auf der Basis von Ampere angekündigt habe, werde dies allgemein im weiteren Verlauf dieses Jahres erwartet. In seiner Keynote-Rede habe der CEO von Nvidia auf die enormen Verbesserungen verwiesen, die Ampere im Bereich Ray-Tracing ermöglichen könne. Unter Ray-Tracing verstehe man die Fähigkeit, unglaublich lebensechte Grafiken mit voller Lichtbrechung zu erstellen. Dies erfordere enorme Mengen an Rechenleistung und sei für computergenerierte Bilder (CGI) in Hollywood-Blockbuster-Filmen eingesetzt worden. Mit Volta sei Ray-Tracing erstmals für PC-Spiele genutzt worden, da die Rechenleistung zu vertretbaren Kosten auf einer Standard-Gaming-Karte untergebracht werden konnte. Mit Ampere werde das Thema auf ein ganz neues Niveau angehoben.
Nvidia habe außerdem eine KI-Engine zur Verbesserung der Ray-Tracing-Leistung eingesetzt. Sie lerne, wie ein Bild mit sehr viel höherer Auflösung aussehe und welche Bewegungsvektoren für Live-Spiele-Videografiken benötigt würden. Damit könne sie vorhersehen, welche Pixel in einem zukünftigen Bild angezeigt werden müssten. Nachdem sich Ray-Tracing über einen Zeitraum von 2 Jahren hinweg immer mehr am Markt durchgesetzt habe, unterstützten inzwischen alle wichtigen Engines für die Spieleentwicklung Ray-Tracing. Gleiches gelte für Hit-Spiele wie Minecraft, Call of Duty: Modern Warfare und Battlefield V sowie die neue PlayStation 5-Konsole, die im weiteren Verlauf dieses Jahres auf den Markt kommen solle. Zukünftige Ampere-Gaming-Karten könnten das Ray-Tracing in PC-Spielen auf die nächste Stufe heben, während virtualisierten Amperes eine mögliche Schlüsselrolle in der Zukunft von Cloud-Gaming-Diensten zugeschrieben werde.
Janus Henderson-Fazit
Ganz gleich, ob Sie Gamer sind, Online-Dienste wie Amazon, Netflix oder Spotify nutzen, die in der Cloud eingerichtet wurden, oder mit KI-Diensten wie Amazon Alexa interagieren – viele Branchenexperten sehen die Einführung von Nvidias Ampere als einen großen Schritt nach vorn, der die Möglichkeit bietet, diese Dienste besser und kostengünstiger zu machen.
Zentrale Erkenntnisse
• Ampere spielt bei Nvidias Vision, Rechenaktivitäten vom Server auf die Ebene des Rechenzentrums zu verlagern und damit die Effizienz deutlich zu steigern, laut Janus Henderson eine Schlüsselrolle.
• Nvidia sieht Ampere als universellen Beschleuniger für Cloud-Arbeitslasten, der sowohl KI-Training als auch Inferenzierung in einem einzigen System effizient durchführen kann.
• Ampere wird enorme Verbesserungen beim Ray-Tracing (naturgetreue Grafiken) ermöglichen, wobei unter anderem eine KI-Engine zur Leistungssteigerung zum Einsatz kommt.
Glossar:
Grafikprozessor (GPU): führt komplexe mathematische und geometrische Berechnungen durch, die für die Grafikwiedergabe erforderlich sind.
Moore‘sches Gesetz: sagt voraus, dass sich die Anzahl der Transistoren, die auf einen Mikrochip passen, alle zwei Jahre ungefähr verdoppeln wird, wodurch die relativen Kosten sinken und die Leistung steigt.
Moore‘scher Druck: bezieht sich auf die seit langem vertretene Auffassung, dass die alle paar Jahre erwartete exponentielle Zunahme der Rechenleistung von Computern ihre Grenze erreicht hat. Da sich die Größenordnung der Chipkomponenten immer mehr der Größe einzelner Atome annähert, ist es heute teurer und technisch schwieriger, die Anzahl der Transistoren und damit die Verarbeitungsleistung für einen bestimmten Chip alle zwei Jahre zu verdoppeln.
Verarbeitung natürlicher Sprache: ein Zweig der KI, der Computern hilft, menschliche Sprache zu verstehen, zu interpretieren und zu manipulieren. Die Verarbeitung natürlicher Sprache bedient sich vieler Disziplinen, darunter die Informatik und die Computerlinguistik, um so die Lücke zwischen menschlicher Kommunikation und Computerverständnis zu schließen.
Virtualisierung: bezieht sich auf eine simulierte bzw. virtuelle Computerumgebung anstelle einer physischen Umgebung. Virtualisierung umfasst häufig computergenerierte Versionen von Hardware, Betriebssystemen, Speichergeräten und mehr. Dies ermöglicht es Organisationen, einen einzelnen physischen Computer oder Server in mehrere virtuelle Maschinen zu partitionieren. Jede virtuelle Maschine kann dann unabhängig interagieren und verschiedene Betriebssysteme oder Anwendungen ausführen, wobei die Ressourcen eines einzelnen Host-Rechners gemeinsam genutzt werden.
Arbeitslast: die Menge der Verarbeitung, die ein Computer zu einem bestimmten Zeitpunkt zu erledigen hat.
KI-Training: auch bekannt als maschinelles Lernen, ist eine Untergruppe der KI, die es Computersystemen ermöglicht, automatisch zu lernen und sich zu verbessern, ohne von einem Menschen programmiert zu werden.
Tiefes Lernen/neuronales Netzwerk: eine Untergruppe des maschinellen Lernens; es handelt sich um eine Reihe von Algorithmen, die darauf abzielen, zugrunde liegende Beziehungen in einem Datensatz durch einen Prozess zu erkennen, der die Funktionsweise des menschlichen Gehirns nachahmt.
KI-Inferenz: bezieht sich auf die Verarbeitung künstlicher Intelligenz. Während sich maschinelles Lernen und tiefes Lernen auf das Training neuronaler Netze beziehen, wendet die KI-Inferenz Wissen aus einem trainierten neuronalen Netzwerkmodell an und verwendet es, um ein Ergebnis abzuleiten.
Sparsity: wird zur Beschleunigung von KI verwendet, indem die für das tiefe Lernen erforderlichen Häufungen der Matrix-Multiplikation reduziert werden, so dass sich die Zeit bis zur Erreichung guter Ergebnisse verkürzt.
NVIDIA Corp.
139,552 $
+3,60 %
Bildherkunft: Adobe Stock: 180707899




")
 - Der unbestrittene König der KI-Chips und schon bald Bitcoin-Mining-Profiteur!")



















Chancen eröffnet")

")


 ins Defense & Space-Depot. Jetzt sind wir bereits über 70 % im Buchgewinn.")