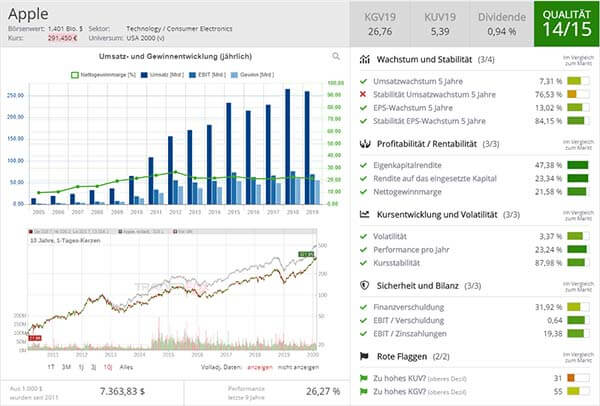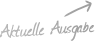

Meta mit neuen Forschungsergebnissen – Kann die KI ihre Arbeit bald selbstständig überprüfen?
Aufklärung über Eigenpositionen: Diese Aktien aus dem Artikel halten TraderFox-Redakteure aktuell
Meta FAIR hat am Freitag, den 18.10., mehrere neue Forschungsergebnisse veröffentlicht, die das Ziel verfolgen, fortgeschrittene maschinelle Intelligenz (AMI) zu erreichen und gleichzeitig die "offene Wissenschaft" sowie die Reproduzierbarkeit zu fördern. Zu der veröffentlichten Arbeit zählt "Meta Segment Anything 2.1 (SAM 2.1)", eine Weiterentwicklung des populären Segment Anything Models für Bilder und Videos. Zudem wurden mehrere Arbeiten präsentiert, die darauf abzielen, die Effizienz großer Sprachmodelle zu verbessern und deren Fähigkeiten zu erweitern.
Self-Taught Evaluator – Entwicklung von KI-Systemen mit weniger menschlicher Beteiligung
Ein weiterer Punkt war die Veröffentlichung des "Self-Taught Evaluator". Dieser zielt darauf ab, den Entwicklungsprozess von KI-Systemen mit weniger menschlicher Beteiligung voranzutreiben. Es handelt sich um eine Methode zur Generierung synthetischer Präferenzdaten, mit der Belohnungsmodelle ("reward models") trainiert werden können, ohne dass menschliche Annotationen erforderlich sind. Seit der Veröffentlichung habe die KI-Gemeinschaft den Ansatz der synthetischen Daten übernommen und nutze ihn, um leistungsstarke Belohnungsmodelle zu trainieren, so das Unternehmen. Durch die Zerlegung komplexer Probleme in kleinere logische Schritte soll die Genauigkeit der Lösungen in Bereichen wie Wissenschaft, Programmierung und Mathematik verbessert werden. Die Meta-Forscher setzen beim Trainieren des Models KI-generierte Daten ein und verzichten weitgehend auf menschliche Eingaben.
Die Fähigkeit, KI zur zuverlässigen Bewertung anderer KI-Systeme einzusetzen, biete einen vielversprechenden Ausblick auf die Entwicklung autonomer KI-Agenten, die aus ihren eigenen Fehlern lernen können, kommentierten zwei Meta-Forscher gegenüber der Nachrichtenagentur Reuters. Jason Weston, einer der Forscher, hoffe, dass die KI in Zukunft in der Lage sein werde, ihre Arbeit eigenständig zu überprüfen und dabei besser werde als der durchschnittliche Mensch. Die Idee, dass eine KI sich selbst etwas beibringen und bewerten könne, sei entscheidend, um das Ziel einer KI auf übermenschlichem Niveau zu erreichen, so Weston weiter.
Während das "Reinforcement Learning from Human Feedback" laut Reuters ein kostspieliges und ineffizientes Verfahren darstellt, könnte das Vorgehen durch den Ansatz selbstverbessernder Modelle überflüssig werden. Bisher hat das Verfahren menschliche Experten erfordert, um die Daten zu beschriften und zu validieren.
























Chancen eröffnet")

")